GC
GC-垃圾回收是一种动态存储管理技术,它可以自动释放那些不再被使用的对象,按照特定的算法来实现资源自动回收。垃圾收集方式
引用计数
堆中的每个对象对应一个引用计数器,每当创建或重新赋值的时候,引用计数器就+1,而当对象出了作用域之后,计数器-1,直到计数器为0,就达到了被回收的条件。
引用计数方式速度较快,不会产生停顿。但是开销较大,因为每个对象都对应了一个计数器。
对象引用遍历
从根集开始扫描,识别出哪些对象可达,哪些不可到达。并利用某种方式标记可达对象。
垃圾收集算法
复制
找到活动对象并拷贝到新的空间。这种算法适合存活对象较少的情况,内存开销较大。
标记清除
从根开始扫描,将活动对象标记。然后再扫描未标记的对象,一次清除。此方法的优点是不需要移动对象,仅对不存活对象操作,适合存活对象较多的情况,容易产生内存碎片。
标记压缩
标记清除的基础上,移动活动对象。缺点是成本较高,优点是没有内存碎片。
分代回收
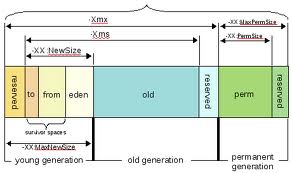
GC是对JVM堆中的对象进行回收,在上一篇博客中,hotspot堆分为young,old和perm三部分。新生对象首先进入young区,随着young区不断的增加,一些老的对象将被移到old区。而perm区主要存储了java class的类型信息和静态变量等。
youngGC
即年轻代垃圾回收,当创建新对象,Eden空间不足时,触发youngGC。有三种选择
1. 串行GC
将Eden中存活的对象移到From->To->Old.适用于单线程,单cpu,新生代较小,要求不高的应用。在client模式或32位机器下默认选择。
启用:-XX:+UseSerialGC
2. 并行回收GC,Parallel Scavenge
多线程执行,适应多CPU,要求较高的应用。在server模式下是默认的。启用:-XX:+UseParallelGC, 在8核心以下的机器上默认为cpu核心数,大于8核,则默认为3+(核心数*5)/8.也可以通过-XX:ParallelGCThreads=8指定。
3. ParNew GC
需配合旧生代使用CMSGC。启用:-XX:+UseParNewGC.可以通过-XX:DisableExplicitGC禁用。
OldGC
1. 旧生代串行GC
算法:标记清除和标记压缩。采用单线程执行,耗时较长,需要暂停应用。client模式或32位机默认采用这种模式。-XX:+PrintGCApplicationStoppedTime可以查看应用暂停时间。
2. 旧生代并行GC
算法:标记压缩算法。采用多线程方式,暂停时间减少。server模式默认采用这种回收方式。
3. 旧生代并发GC
采用标记清除算法。对GC进行并发执行,大大缩短应用暂停时间,但是整体GC时间会加长。启用方式:-XX:+UseConcMarkSweepGC。可以通过-XX:ParallelCMSThreads=10指定并发线程数。通过-XX:+CMSClassUnloadingEnabled来启用持久代CMS.
垃圾整理:使用-XX:UseCMSCompactAtFullCollection每次fullGC后都会启动垃圾整理.-XX:CMSFullGCsBeforeCompaction=2表示2次fullGC后开始整理。
fullGC
旧生代和持久代GC时,即是对新生代,旧生代持久代都GC,FullGC。
执行时,先对新生代GC,可以通过-XX:ScanengeBeforeFullGC禁止fullGC时对新生代GC,然后对旧生代持久代进行GC。
触发时机:
1. system.gc,可以通过-XX:DisableExplicitGC禁用。
2. 旧生代空间不足
3. 持久代空间满
4. CMSGC时出现promotion failed
5. 统计youngGC后要移到旧生代的对象大于旧生代剩余空间
查看JVM使用的GC算法
找到java进程ID,使用jmap命令:
打印之前先看一下启动参数:
下面是jvm-heap信息:
jmap -heap {pid}
会打印出JVM的基本信息,包括分区信息,回收算法等。打印之前先看一下启动参数:
java -server -Xms512m -Xmx512m -XX:NewSize=100m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=58 -XX:PermSize=64m -XX:MaxPermSize=64m -XX:ThreadStackSize=512
下面是jvm-heap信息:
Attaching to process ID 31410, please wait... Debugger attached successfully. Server compiler detected. JVM version is 20.8-b03 using parallel threads in the new generation. using thread-local object allocation. Concurrent Mark-Sweep GC Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 536870912 (512.0MB) NewSize = 104857600 (100.0MB) MaxNewSize = 283508736 (270.375MB) OldSize = 314572800 (300.0MB) NewRatio = 7 SurvivorRatio = 8 PermSize = 67108864 (64.0MB) MaxPermSize = 67108864 (64.0MB) Heap Usage: New Generation (Eden + 1 Survivor Space): capacity = 94371840 (90.0MB) used = 7155464 (6.823982238769531MB) free = 87216376 (83.17601776123047MB) 7.582202487521702% used Eden Space: capacity = 83886080 (80.0MB) used = 6906936 (6.586967468261719MB) free = 76979144 (73.41303253173828MB) 8.233709335327148% used From Space: capacity = 10485760 (10.0MB) used = 248528 (0.2370147705078125MB) free = 10237232 (9.762985229492188MB) 2.370147705078125% used To Space: capacity = 10485760 (10.0MB) used = 0 (0.0MB) free = 10485760 (10.0MB) 0.0% used concurrent mark-sweep generation: capacity = 432013312 (412.0MB) used = 7523480 (7.174949645996094MB) free = 424489832 (404.8250503540039MB) 1.7414926325233238% used Perm Generation: capacity = 67108864 (64.0MB) used = 39960504 (38.10930633544922MB) free = 27148360 (25.89069366455078MB) 59.545791149139404% used