1. 安装Openssh,在cydia中搜索安装即可;
2. 安装MobileTerminal,打开后可以修改root密码,默认密码是alpine
3. 安装cydelete,会自动安装curl和apt-get,这样缺少什么命令就可以安装了
4. 安装appsync,可以直接安装ipa包
5. 安装sbsettings组件,可以方便的通过顶部横栏呼出设定窗口,设置飞行模式,3G,wifi等的开关;
6. 搜狗输入法
7. bitesms,方便在锁屏界面直接回复短信。随着微信的发展,短信发的越来越少了。
2013年2月18日星期一
2013年2月16日星期六
Sbt从Sonatype中获取依赖和向Sonatype发布jar
获取依赖
在build.sbt中添加:
resolvers += "Sonatype OSS Snapshots" at "https://oss.sonatype.org/content/repositories/snapshots"
向Sonatype发布jar
官方文档
官方文档
publishTo <<= version { v: String =>
val nexus = "https://oss.sonatype.org/"
if (v.trim.endsWith("SNAPSHOT"))
Some("snapshots" at nexus + "content/repositories/snapshots")
else
Some("releases" at nexus + "service/local/staging/deploy/maven2")
}
publishMavenStyle := true
publishArtifact in Test := false
pomIncludeRepository := { _ => false }
pomExtra := (
<url>http://your.project.url</url>
<licenses>
<license>
<name>BSD-style</name>
<url>http://www.opensource.org/licenses/bsd-license.php</url>
<distribution>repo</distribution>
</license>
</licenses>
<scm>
<url>git@github.com:your-account/your-project.git</url>
<connection>scm:git:git@github.com:your-account/your-project.git</connection>
</scm>
<developers>
<developer>
<id>you</id>
<name>Your Name</name>
<url>http://your.url</url>
</developer>
</developers>
)
HTTPS(SSL)原理
SSL
SSL是由Netscape公司提出的安全协议,利用数据加密、身份验证和消息完整性验证为网络中传输的数据提供安全性保证。数据传输的机密性
对称加密算法:加密解密使用同样的密钥,常用算法:RC2、RC4、IDEA、DES、Triple DES、AES以及Camellia;
非对称加密算法:加密解密使用不同的密钥,其中一个是公开的密钥,用来加密。另外一个是私有的私钥,用于解密。常用算法:RSA、Diffie-Hellman、DSA及Fortezza
单向散列函数:用于计算消息的特征值,例如MD5,SHA1,SHA256
非对称加密算法:加密解密使用不同的密钥,其中一个是公开的密钥,用来加密。另外一个是私有的私钥,用于解密。常用算法:RSA、Diffie-Hellman、DSA及Fortezza
单向散列函数:用于计算消息的特征值,例如MD5,SHA1,SHA256
利用PKI保证公钥的真实性
PKI通过数字证书来发布用户的公钥,并提供了验证公钥真实性的机制。数字证书(简称证书)是一个包含用户的公钥及其身份信息的文件,证明了用户与公钥的关联。数字证书由权威机构——CA签发,并由CA保证数字证书的真实性。
利用非对称加密保证密钥本身的安全
SSL利用非对称密钥算法加密密钥的方法实现密钥交换,保证第三方无法获取该密钥。
消息完整性
为了避免网络中传输的数据被非法篡改,SSL利用基于MD5或SHA的MAC算法来保证消息的完整性。

如图,消息的任何改变,都会引起输出的固定长度数据产生变化。通过比较MAC值,可以保证接收者能够发现消息的改变。
MAC算法需要密钥的参与,因此没有密钥的非法用户在改变消息的内容后,无法添加正确的MAC值,从而保证非法用户无法随意修改消息内容。
SSL分层结构

- SSL握手协议:是SSL协议非常重要的组成部分,用来协商通信过程中使用的加密套件(加密算法、密钥交换算法和MAC算法等)、在服务器和客户端之间安全地交换密钥、实现服务器和客户端的身份验证。
- SSL密码变化协议:客户端和服务器端通过密码变化协议通知对端,随后的报文都将使用新协商的加密套件和密钥进行保护和传输。
- SSL警告协议:用来向通信对端报告告警信息,消息中包含告警的严重级别和描述。
- SSL记录协议:主要负责对上层的数据(SSL握手协议、SSL密码变化协议、SSL警告协议和应用层协议报文)进行分块、计算并添加MAC值、加密,并把处理后的记录块传输给对端。
SSL的握手过程
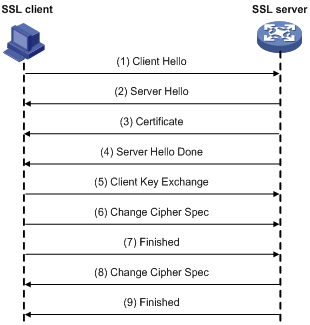
图:只认证服务器SSL的握手过程
- SSL客户端通过Client Hello消息将它支持的SSL版本、加密算法、密钥交换算法、MAC算法等信息发送给SSL服务器。
- SSL服务器确定本次通信采用的SSL版本和加密套件,并通过Server Hello消息通知给SSL客户端。如果SSL服务器允许SSL客户端在以后的通信中重用本次会话,则SSL服务器会为本次会话分配会话ID,并通过Server Hello消息发送给SSL客户端。
- SSL服务器将携带自己公钥信息的数字证书通过Certificate消息发送给SSL客户端。
- SSL服务器发送Server Hello Done消息,通知SSL客户端版本和加密套件协商结束,开始进行密钥交换。
- SSL客户端验证SSL服务器的证书合法后,利用证书中的公钥加密SSL客户端随机生成的premaster secret,并通过Client Key Exchange消息发送给SSL服务器。
- SSL客户端发送Change Cipher Spec消息,通知SSL服务器后续报文将采用协商好的密钥和加密套件进行加密和MAC计算。
- SSL客户端计算已交互的握手消息(除Change Cipher Spec消息外所有已交互的消息)的Hash值,利用协商好的密钥和加密套件处理Hash值(计算并添加MAC值、加密等),并通过Finished消息发送给SSL服务器。SSL服务器利用同样的方法计算已交互的握手消息的Hash值,并与Finished消息的解密结果比较,如果二者相同,且MAC值验证成功,则证明密钥和加密套件协商成功。
- 同样地,SSL服务器发送Change Cipher Spec消息,通知SSL客户端后续报文将采用协商好的密钥和加密套件进行加密和MAC计算。
- SSL服务器计算已交互的握手消息的Hash值,利用协商好的密钥和加密套件处理Hash值(计算并添加MAC值、加密等),并通过Finished消息发送给SSL客户端。SSL客户端利用同样的方法计算已交互的握手消息的Hash值,并与Finished消息的解密结果比较,如果二者相同,且MAC值验证成功,则证明密钥和加密套件协商成功。
2013年2月7日星期四
KAFKA在统计系统中的应用
Kafka
kafka是LinkedIn开源的一款分布式的发布-订阅消息系统,它具有:
1. 通过O(1)的磁盘结构持久化存储消息,即使TB级的数据也能保持长期稳定;
2. 高吞吐率:即使非常普通的硬件,kafka也能支持每秒数十万的消息;
3. 支持通过kafka服务器和消费集群来分区消息;
4. 支持Hadoop并行加载;
设计流程

通过集成kafka和log4j在各个需要采集日志的系统进行日志采集,日志统一发送到kafka的消息队列。再通过定时运行kafka-hadoop的作业,将数据从KAFKA同步到hadoop的HDFS中。hadoop的各类map-reduce作业可以对数据进行统计,存储到db或缓存中。
安装
首先安装kafka,下载kafka到本地,然后执行:
> tar xzf kafka-<VERSION>.tgz > cd kafka-<VERSION> > ./sbt update > ./sbt package
启动zookeeper
> bin/zookeeper-server-start.sh config/zookeeper.properties [2010-11-21 23:45:02,335] INFO Reading configuration from: config/zookeeper.properties...
启动kafka
> bin/kafka-server-start.sh config/server.properties jkreps-mn-2:kafka-trunk jkreps$ bin/kafka-server-start.sh config/server.properties [2010-11-21 23:51:39,608] INFO starting log cleaner every 60000 ms (kafka.log.LogManager) [2010-11-21 23:51:39,628] INFO connecting to ZK: localhost:2181 (kafka.server.KafkaZooKeeper)...发送一些消息
> bin/kafka-console-producer.sh --zookeeper localhost:2181 --topic test This is a message This is another message
查看消息
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning This is a message This is another message
至此,kafka已经启动成功。
安装hadoop,下载hadoop0.20.2,按照hadoop的操作手册安装,此处省略安装过程。
配置log4j和kafka-log
#配置KAFKA
#Hostname表示应用的名称
#Topic表示打印日志生成的目录名
log4j.appender.KAFKA=com.comp.kafka.AsyncKafkaAppender
log4j.appender.KAFKA.topic=TOPIC
log4j.appender.KAFKA.bufferSize = 10
log4j.appender.KAFKA.brokerList=0:kafka-server-ip:9092
log4j.appender.KAFKA.serializerClass=kafka.serializer.StringEncoder
log4j.appender.KAFKA.hostname=APP-NAME
log4j.appender.KAFKA.layout=org.apache.log4j.PatternLayout
log4j.appender.KAFKA.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.logger.com.comp= DEBUG, KAFKA
配置中,配置了kafka的ip和端口,并设置了topic和序列化类和pattern。
AsyncKafkaAppender是继承了log4j的AsyncAppender,是log4j异步发送日志的模式,当log达到bufferSize的大小时,会统一由log4j异步执行打印操作。代码如下:
AsyncKafkaAppender是继承了log4j的AsyncAppender,是log4j异步发送日志的模式,当log达到bufferSize的大小时,会统一由log4j异步执行打印操作。代码如下:
public class AsyncKafkaAppender extends AsyncAppender {
private java.lang.String topic;
private java.lang.String serializerClass;
private java.lang.String zkConnect;
private java.lang.String brokerList;
private java.lang.String hostname;
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
public String getSerializerClass() {
return serializerClass;
}
public void setSerializerClass(String serializerClass) {
this.serializerClass = serializerClass;
}
public String getZkConnect() {
return zkConnect;
}
public void setZkConnect(String zkConnect) {
this.zkConnect = zkConnect;
}
public String getBrokerList() {
return brokerList;
}
public void setBrokerList(String brokerList) {
this.brokerList = brokerList;
}
public String getHostname() {
return hostname;
}
public void setHostname(String hostname) {
this.hostname = hostname;
}
@Override
public void activateOptions() {
super.activateOptions();
synchronized (this) {
KafkaLog4jAppender kafka = new KafkaLog4jAppender();
kafka.setLayout(getLayout());
kafka.setHostname(getHostname());
kafka.setBrokerList(getBrokerList());
kafka.setSerializerClass(getSerializerClass());
kafka.setZkConnect(getZkConnect());
kafka.setTopic(getTopic());
kafka.activateOptions();
addAppender(kafka);
}
}
@Override
public boolean requiresLayout() {
return true;
}
}
这时我们就可以撰写一个测试代码,测试log是否已经发送到了kafka。KAFKA消息发送到Hadoop
在kafka的contrib目录的hadoop-consumer中有一系列的文件,包括脚本,jar,配置文件等。我们可以直接使用这个目录下的脚本进行定时数据同步。
需要先修改test目录下的test.properties:
# kafka的topic名称 kafka.etl.topic=TOPIC # hdfs location of jars hdfs.default.classpath.dir=/tmp/kafka/lib # number of test events to be generated event.count=1000 # hadoop id and group hadoop.job.ugi=kafka,hadoop # kafka server uri kafka.server.uri=tcp://localhost:9092 # hdfs location of input directory input=hdfs://localhost:9000/tmp/kafka/data # hdfs location of output directory output=hdfs://localhost:9000/tmp/kafka/output # limit the number of events to be fetched; # value -1 means no limitation kafka.request.limit=-1 # kafka parameters client.buffer.size=1048576 client.so.timeout=60000
修改topic名称以及对应hadoop的input,output目录。
首先生成offset,执行:
现在只需要撰写一些map-reduce作业,就可以利用hadoop进行数据统计了。
首先生成offset,执行:
./run-class.sh kafka.etl.impl.DataGenerator test/test.properties然后拷贝依赖的jar文件:
./copy-jars.sh ${hdfs.default.classpath.dir}
最后执行hadoop任务:./run-class.sh kafka.etl.impl.SimpleKafkaETLJob test/test.properties执行完成后,运行hadoop脚本查看是否已经在output目录生成数据:
bin/hadoop fs -cat /tmp/kafka/output/part-00000 | wc -l至此,从日志从各个系统已经成功收集到hadoop的HDFS文件系统中。
现在只需要撰写一些map-reduce作业,就可以利用hadoop进行数据统计了。
KAFKA消息清除
# The minimum age of a log file to be eligible for deletion log.retention.hours=168 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.file.size=536870912
在配置中,如果一个log file距离上一次写入时间达到168小时,也就是一周,会自动清除这个日志文件;日志文件的上限大小是536870912,超过这个大小会创建新的日志文件。
订阅:
博文 (Atom)